代码示例
from fake_useragent import UserAgent
import requests
import re
url='https://www.ctfhub.com/#/calendar'
# rsp = requests.get(url);
# print(rsp.text)
url='https://api.ctfhub.com/User_API/Event/getAllICS'
# 比赛时间
# DTSTART:20220415T160000Z
# DTEND:20220417T160000Z
# url
# URL:https://dctf.dragonsec.si/
# DESCRIPTION:线上 | Jeopardy[解题] | https://dctf.dragonsec.si/
pattern0 = r'SUMMARY:(.*)'
pattern1 = r'DTSTART:(.*)'
pattern2 = r'DTEND:(.*)'
pattern3 = r'URL:(.*)'
def deal_time(a):
pattern0 = r'.{4}'
pattern1 = r'2022(.{2})'
pattern2 = r'2022.{2}(.{2})'
year = re.findall(pattern0,a)
month = re.findall(pattern1,a)
day = re.findall(pattern2,a)
print(year[0]+'年'+month[0]+'月'+day[0]+'日')
resp = requests.get(url);
a = re.findall(pattern0,resp.text)
b = re.findall(pattern1,resp.text)
c = re.findall(pattern2,resp.text)
d = re.findall(pattern3,resp.text)
print("[长野原机器人的比赛推送]")
i=0
while i< len(a):
print("比赛名称:")
print(a[i])
print("比赛时间:")
deal_time(b[i])
print('~')
deal_time(c[i])
print("比赛url:")
print(d[i])
i=i+1
# deal_time(b[0])
print("消息来源:ctfhub")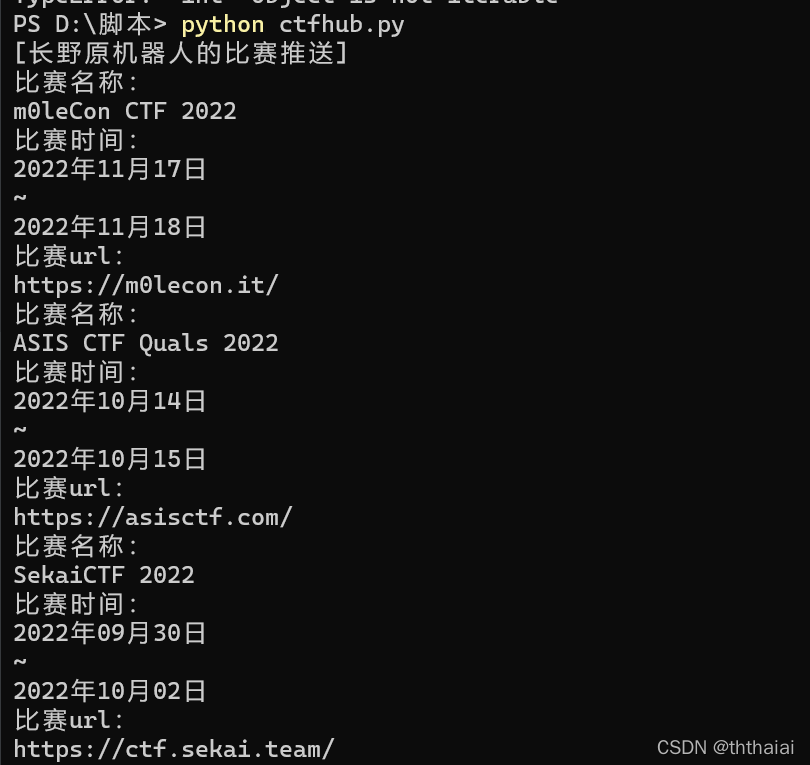
需要完善的点:api可以加上ctftime的,时间可以通过进一步访问url来进行双重确认,时间没有筛选,最好和qq,微信机器人等结合